4. MLlib(機械学習)
この章では「パーソナライズされた映画のリコメンド」という実例を通じて機械学習を学びます。 ここで使用するデータは、MovieLensによって取得された、ユーザが実際に映画を評価したデータ群で、以下のような規模のものです。
- リコメンド総数:約1,000万件
- ユーザ数:約72,000ユーザ
- 映画の種類:約10,000本
上記のデータは、training/data/movielens/largeに格納されています。 また高速に処理を行うためにデータ規模を小さくしたものがtraining/data/movielens/mediumに格納されています。 このデータは以下のような規模にそれぞれ縮小したデータセットです。
- リコメンド総数:約100万件
- ユーザ数:約6,000ユーザ
- 映画の種類:約4,000本
4-1. データセットの説明
training/data/movielens/mediun ディレクトリの中を見ると、以下のようなファイルが入っていることがわかります。
$ cd ${HOME}/training/data/movielens/medium
$ ls -lh
合計 24M
-rw-r--r-- 1 kiuchi kiuchi 0 6月 19 2014 Icon
-rw------- 1 kiuchi kiuchi 5.1K 6月 19 2014 README
-rw------- 1 kiuchi kiuchi 168K 6月 19 2014 movies.dat
-rw------- 1 kiuchi kiuchi 24M 6月 19 2014 ratings.dat
-rw------- 1 kiuchi kiuchi 132K 6月 19 2014 users.dat
[kiuchi@spark-single medium]$
これから使用するのは “ratings.dat” と “movies.dat” です。 “ratings.dat”の内容はテキストデータで、以下のフォーマットで格納されています。
<ユーザID>::<ムービーID>::<評価>::<タイムスタンプ>
また “movies.dat” の内容は同様に以下のフォーマットのテキストデータです。
<ムービーID>::<映画のタイトル>::<映画のジャンル>
4-2. 協調フィルタリング
協調フィルタリングとは、リコメンドエンジンに一般的に用いられているアルゴリズムで、表の中の空欄を、実際に埋めた場合にそうなると思われる値を算出します。 ここでいう”表”とは今回の場合、”ユーザ”と”映画”をそれぞれ軸に持ち、それぞれの欄に”評価”が入っている表になります。 Sparkは現時点では「モデルベース協調フィルタリング」を実装しており、それによって表中の空欄に入る値を算出します。 その際に、同様にSparkが有する「交互最小二乗法(Alternating Least Squares, ALS)[8]」によって潜在変数セットを算出し、傾向性を算出します。
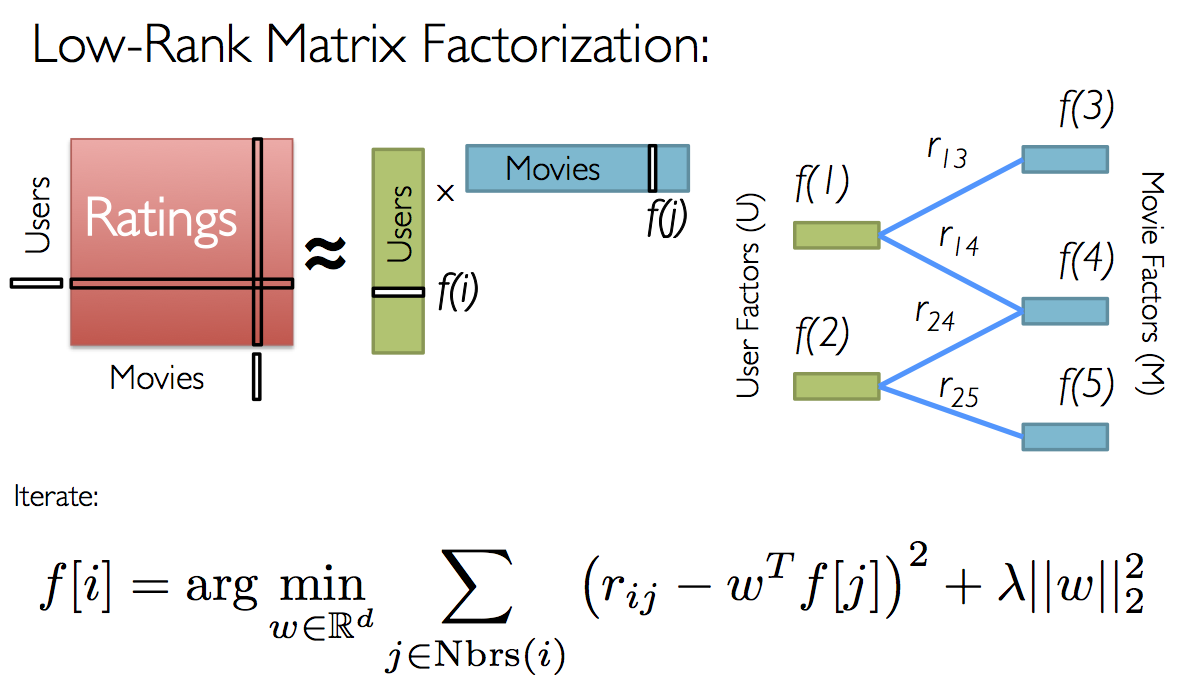
4-3. サンプルコードの実行
それでは実際のサンプルコードを見てみましょう。
training/machine-learning/scala/solution/MovieLensALS.scala
import java.io.File
import scala.io.Source
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd._
import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
object MovieLensALS {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
if (args.length != 2) {
println("Usage: /path/to/spark/bin/spark-submit --driver-memory 2g --class MovieLensALS " +
"target/scala-*/movielens-als-ssembly-*.jar movieLensHomeDir personalRatingsFile")
sys.exit(1)
}
// set up environment
val conf = new SparkConf()
.setAppName("MovieLensALS")
.set("spark.executor.memory", "2g")
val sc = new SparkContext(conf)
// load personal ratings
val myRatings = loadRatings(args(1))
val myRatingsRDD = sc.parallelize(myRatings, 1)
// load ratings and movie titles
val movieLensHomeDir = args(0)
val ratings = sc.textFile(new File(movieLensHomeDir, "ratings.dat").toString).map { line =>
val fields = line.split("::")
// format: (timestamp % 10, Rating(userId, movieId, rating))
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
val movies = sc.textFile(new File(movieLensHomeDir, "movies.dat").toString).map { line =>
val fields = line.split("::")
// format: (movieId, movieName)
(fields(0).toInt, fields(1))
}.collect().toMap
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from "
+ numUsers + " users on " + numMovies + " movies.")
// split ratings into train (60%), validation (20%), and test (20%) based on the
// last digit of the timestamp, add myRatings to train, and cache them
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6)
.values
.union(myRatingsRDD)
.repartition(numPartitions)
.cache()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val test = ratings.filter(x => x._1 >= 8).values.cache()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)
// train models and evaluate them on the validation set
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation) = " + validationRmse + " for the model trained with rank = "
+ rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
// evaluate the best model on the test set
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ ", and numIter = " + bestNumIter + ", and its RMSE on the test set is " + testRmse + ".")
// create a naive baseline and compare it with the best model
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse =
math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean)
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")
// make personalized recommendations
val myRatedMovieIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get
.predict(candidates.map((0, _)))
.collect()
.sortBy(- _.rating)
.take(50)
var i = 1
println("Movies recommended for you:")
recommendations.foreach { r =>
println("%2d".format(i) + ": " + movies(r.product))
i += 1
}
// clean up
sc.stop()
}
/** Compute RMSE (Root Mean Squared Error). */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = {
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
/** Load ratings from file. */
def loadRatings(path: String): Seq[Rating] = {
val lines = Source.fromFile(path).getLines()
val ratings = lines.map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}.filter(_.rating > 0.0)
if (ratings.isEmpty) {
sys.error("No ratings provided.")
} else {
ratings.toSeq
}
}
}
以下のようにbuild.sbtを修正します。
training/machine-learning/scala/build.sbt
import AssemblyKeys._
assemblySettings
name := "movielens-als"
version := "0.1"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" % "spark-mllib_2.10" % "1.6.0" % "provided"
以下のようにbuild.propertiesファイルを作成します。
training/machine-learning/scala/project/build.properties
sbt.version=0.13.9
以下のようにサンプルデータを作成します。
$ cd ${HOME}/training/machine-learning/
$ cp personalRatings.txt.template personalRatings.txt
作成したpersonalRatings.txtを編集し、”?”を1~5の数値に置き換えます。 これがこれらの映画に対するあなたの評価になります。
training/machine-learning/personalRatings.txt
0::1::?::1400000000::Toy Story (1995)
0::780::?::1400000000::Independence Day (a.k.a. ID4) (1996)
0::590::?::1400000000::Dances with Wolves (1990)
0::1210::?::1400000000::Star Wars: Episode VI - Return of the Jedi (1983)
0::648::?::1400000000::Mission: Impossible (1996)
0::344::?::1400000000::Ace Ventura: Pet Detective (1994)
0::165::?::1400000000::Die Hard: With a Vengeance (1995)
0::153::?::1400000000::Batman Forever (1995)
0::597::?::1400000000::Pretty Woman (1990)
0::1580::?::1400000000::Men in Black (1997)
0::231::?::1400000000::Dumb & Dumber (1994)
以下のようにコンパイルします。
$ cd ${HOME}
$ cd training/machine-learning/scala/
$ mkdir build
$ cd build
$ ln -s ${HOME}/spark-1.6.0/sbt/bin/sbt-launch.jar ./sbt-launch-0.13.9.jar
$ cd ..
$ cp solution/MovieLensALS.scala .
$ ${HOME}/spark-1.6.0/sbt/sbt assembly
以下のように実行すると、あなたの評価に基づくおすすめの映画がリストアップされます。
$ SPARK_MEM=4g ~/spark-1.6.0/bin/spark-submit --class MovieLensALS target/scala-2.10/movielens-als-assembly-0.1.jar ~/training/data/movielens/medium/ ../personalRatings.txt
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/28 22:39:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/06/28 22:39:14 INFO Slf4jLogger: Slf4jLogger started
15/06/28 22:39:14 INFO Remoting: Starting remoting
15/06/28 22:39:14 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.20.97:49233]
(略)
Movies recommended for you:
1: Conceiving Ada (1997)
2: Love Serenade (1996)
3: Guantanamera (1994)
4: Belly (1998)
5: Stiff Upper Lips (1998)
6: Saltmen of Tibet, The (1997)
7: Good Earth, The (1937)
8: Across the Sea of Time (1995)
9: Smashing Time (1967)
10: Spitfire Grill, The (1996)
11: Firelight (1997)
12: For Love of the Game (1999)
13: First Love, Last Rites (1997)
14: Duets (2000)
15: Window to Paris (1994)
16: Ayn Rand: A Sense of Life (1997)
17: King and I, The (1999)
18: Better Than Chocolate (1999)
19: Brother Minister: The Assassination of Malcolm X (1994)
20: Bewegte Mann, Der (1994)
21: Crazy in Alabama (1999)
22: Zachariah (1971)
23: And the Ship Sails On (E la nave va) (1984)
24: Mr. Jones (1993)
25: Jakob the Liar (1999)
26: Among Giants (1998)
27: Dangerous Beauty (1998)
28: No Mercy (1986)
29: Small Wonders (1996)
30: Against All Odds (1984)
31: I'm the One That I Want (2000)
32: Steal Big, Steal Little (1995)
33: H.O.T.S. (1979)
34: Cement Garden, The (1993)
35: Stealing Home (1988)
36: I Love You, Don't Touch Me! (1998)
37: City of Angels (1998)
38: Wisdom (1986)
39: Gossip (2000)
40: Where the Heart Is (2000)
41: Long Walk Home, The (1990)
42: Horseman on the Roof, The (Hussard sur le toit, Le) (1995)
43: Steel Magnolias (1989)
44: Eighth Day, The (Le Huiti�me jour ) (1996)
45: Patch Adams (1998)
46: Armageddon (1998)
47: Best Laid Plans (1999)
48: Rules of Engagement (2000)
49: Jupiter's Wife (1994)
50: Mr. Holland's Opus (1995)
15/06/28 22:40:26 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15/06/28 22:40:26 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
15/06/28 22:40:27 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
$
4-4. 解説(1)-データの読み出し
それでは個々の処理内容について解説します。
val conf = new SparkConf()
.setAppName("MovieLensALS")
.set("spark.executor.memory", "2g")
val sc = new SparkContext(conf)
Sparkにおけるどのような処理であっても、最初にSparkConfオブジェクトを作成し、SparkContextオブジェクトを作成する際の引数として与えます。 spark-submitコマンドで理解される、アプリケーション名”MovieLensALS”と、必要なメモリ量”2g(=2GB)”を指定します。 アプリケーション名はWebUI(http://sparkホスト:4040)にも表示されるため、各種情報を判別するのに役立ちます。
val movieLensHomeDir = args(0)
val ratings = sc.textFile(new File(movieLensHomeDir, "ratings.dat").toString).map { line =>
val fields = line.split("::")
// format: (timestamp % 10, Rating(userId, movieId, rating))
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
次に”ratings.dat”ファイルから映画の評価データを読み込みます。 評価データファイルはテキストファイルであり、”::(コロン コロン)”が区切り文字であることを思い出してください。 上記のコードは評価データの各行を読み出し、”::”で区切ったものを要素にもつタプル型に変換し、RDDを作成します。 要素の中のタイムスタンプについては最後の1文字(もともとのタイムスタンプを10で割った余り)をランダムキーとして使用しています。 Ratingクラスは”ユーザID(Int)”、”ムービーID(Int)”、”評価(Double)”で構成されるタプル型のラッパークラスになっています。
val movies = sc.textFile(new File(movieLensHomeDir, "movies.dat").toString).map { line =>
val fields = line.split("::")
// format: (movieId, movieName)
(fields(0).toInt, fields(1))
}.collect().toMap
上記のコードは、同様に”movies.dat”ファイルから映画データを読み込み、タプル型に変換した上でRDDを生成し、最後にtoMap関数でマップ(キー, 値のセット)に変換します。
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from "
+ numUsers + " users on " + numMovies + " movies.")
上記のコードで何個の評価データ、映画データを読み込んだかを表示します。
4-5. 解説(2)-データの分割
これからMLlibの関数であるALSを使い、RDD[Rating]を入力とするMatrixFactorizationModelをトレーニングします。
ALSはトレーニング用のパラメータとして、Matrix FactorとRegurarization Constantsを持っています。
最適な組み合わせを見つけるために、これからデータを3つのオーバーラップしないサブセットに分割します。 それぞれ以下のようになります。
- training: トレーニング用
- test: テスト用
- validation: 評価用
データを分割するために、日付の最後の一桁を使用し、キャッシュします。
まずtrainingデータセットを基に複数のモデルをトレーニングし、RMSE(Root Mean Squared Error)を基にしたvalidationデータセットで評価します。 最後にtestデータセットで最適なモデルを決定しました。 またtrainingデータセットに、あなたの評価(training/machine-learning/personalRatings.txtでセットしたもの)を含め、リコメンドのために使用します。 training, validation, testデータセットはいずれも複数回読み出されるため、それぞれcache()命令を呼び出すことでメモリ上にキャッシュされます。
Matrix Factorization: 行列因子分解。次元削減手法の一つ。(参考),(参考)
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6)
.values
.union(myRatingsRDD)
.repartition(numPartitions)
.cache()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val test = ratings.filter(x => x._1 >= 8).values.cache()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)
データの分割後、それぞれのデータセットの個数は以下のようになります。
Training: 602251, validation: 198919, test: 199049.
4-6. 解説(3)-ALSを用いたトレーニング
ここではALS.trainを用いていくつかのモデルをトレーニングし、評価したのちに最適なモデルを選択します。
ALSのトレーニングパラメータには、rank(潜在因子の数)、lambda(Regularization Constant, 正則化定数)、iterations(繰り返し回数)があります。 ALS.trainメソッドは以下のように使用されます。
val ranks = List(8, 12)
val lambdas = List(1.0, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation) = " + validationRmse + " for the model trained with rank = "
+ rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
理想的にはベストなモデルを探索するためには各パラメータの変更範囲を大きくすることが望ましいのですが、処理時間の制約から、今回は以下のパラメータで8モデルの組み合わせを評価することにします。
- rank(2個): 8 および 12
- lambda(2個): 1.0 および 10.0
- iteration(2個): 10 および 20
そして提供されているメソッドであるcomputeRmseを使って各モデルそれぞれでvalidation(サブセット)のRMSEを計算します。 validationのRMSEが一番小さかったモデルが選ばれ、そのモデルのtestセットのRMSEが最終計量として使われます。
Sparkはモデルをトレーニングするのに1~2分掛かるかもしれません。 出来ましたらスクリーン上に以下が見えるはずです。 実行ごとに答え自体が多少異なるかもしれません。
The best model was trained with rank 8 and lambda 10.0, and numIter = 10, and its RMSE on test is 0.8808492431998702.
4-7. あなたにお勧めする映画
このチュートリアルの最後の部分として、モデルがあなたにどんな映画をお勧めするかを見てみましょう。
すべての予想が出ましたら、お勧めTop50をリストさせてあなたに合っているかを確かめて下さい。
val myRatedMovieIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get
.predict(candidates.map((0, _)))
.collect()
.sortBy(- _.rating)
.take(50)
var i = 1
println("Movies recommended for you:")
recommendations.foreach { r =>
println("%2d".format(i) + ": " + movies(r.product))
i += 1
}
以下の出力と似ているはずです。
Movies recommended for you:
1: Silence of the Lambs, The (1991)
2: Saving Private Ryan (1998)
3: Godfather, The (1972)
4: Star Wars: Episode IV - A New Hope (1977)
5: Braveheart (1995)
6: Schindler's List (1993)
7: Shawshank Redemption, The (1994)
8: Star Wars: Episode V - The Empire Strikes Back (1980)
9: Pulp Fiction (1994)
10: Alien (1979)
...
結果が違うことがあり得ることとデータセットが古いのでここ10年の映画は出てこないことを理解してください。
4-8. エクササイズ
4-8-(1). ナイーブベースラインと比較する
ALSは意味のあるモデルを出力するのでしょうか? これを確かめるに評価結果を平均的な評価しか出力しないナイーブベースラインモデルと比較します。 ベースラインのRMSEを計算するのは複雑ではありません。
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse =
math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean)
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")
出力は以下と似ているはずです。
The best model improves the baseline by 20.96%.
トレーニングされたモデルはナイーブベースラインより成果を出すことは明らかなようです。 しかし間違ったトレーニングパラメータを組み合わせると、ナイーブベースラインより悪い結果となります。 したがって正しいパラメータのセットを選ぶことがこのタスクではかなり重要です。
4-8-(2). マトリックス因子を加える
このチュートリアルはトレーニングセットにあなたの評価を付け加えます。お勧めを出すより良い方法はまずMatrix Factorizationモデルをトレーニングして、モデルにあなたの評価を備えます。もしこの方法に興味が湧きましたらMatrixFactorizationModelの実行方法をみて新しいユーザのためにモデルに更新する方法を確認してください。
もしあなたへのお勧めやソースコードが先に見たいならば、答えはmachine-learning/scala/solutionに載っています。